

Зачем вообще нужны утилиты для орфографии
Утилиты для анализа и исправления орфографических ошибок давно перестали быть «приставкой» к офисному пакету и превратились в отдельный класс программных решений. Они контролируют не только буквы в словах, но и согласование, пунктуационные паттерны, стилистические огрехи. На их основе строятся редакторы, плагины к IDE, браузерные расширения и корпоративные серверы проверки текста. Важно понимать, как такие инструменты принимают решение: где реальная ошибка, а где авторская особенность, профессиональный жаргон или намеренное отступление от нормы.
Ключевые термины и базовые понятия
Под «орфографической ошибкой» будем понимать отклонение написания слова от кодифицированной нормы, закреплённой в словарях. «Грамматическая ошибка» — нарушение морфологических или синтаксических правил: неправильное окончание, падеж, форма числа, сбой в управлении. «Утилита проверки» — это программа или сервис, который автоматически выявляет такие отклонения и предлагает правки. Термин «контекстная проверка» обозначает способность системы анализировать соседние слова, а не только изолированное написание, что критически важно для омонимов и часто путаемых пар.
Как устроена утилита: диаграмма в словах
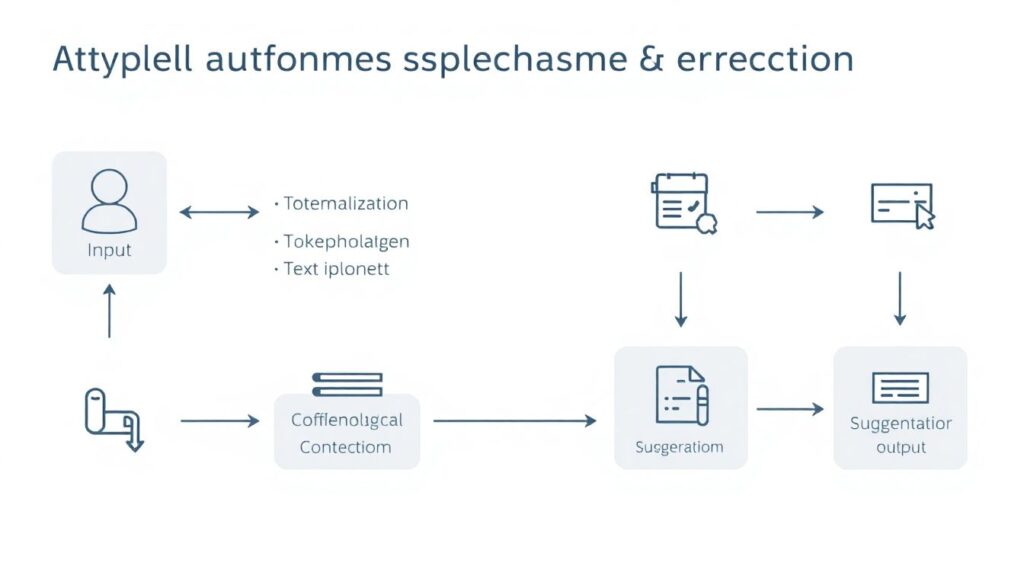
Типичный сервис автоматической проверки и исправления орфографических ошибок можно описать в виде текстовой диаграммы: «Ввод → Нормализация текста → Токенизация → Морфологический анализ → Поиск несоответствий словарю → Контекстные правила → Модели машинного обучения → Генерация подсказок → Вывод». На шаге нормализации убираются мусорные символы, на этапе токенизации текст режется на предложения и слова. Далее морфологический модуль сопоставляет лексемы с грамматическими тегами, а контекстные правила и статистические модели уточняют, является ли подозрительный фрагмент реальной ошибкой.
Словарный подход: простой, быстрый, но слепой к контексту
Классическая программа для проверки орфографических ошибок в русском языке опирается на большой словарь правильных форм. Алгоритм предельно прямолинейный: если слово не нашлось в словаре, оно помечается как ошибка; дальше через расстояние Левенштейна и похожие эвристики предлагаются ближайшие варианты. Такой метод очень быстр и предсказуем, легко переносится между платформами и подходит для встроенных редакторов. Однако у него есть очевидный минус: нераспознанные термины, имена, сленг и заимствования либо массово помечаются как ошибки, либо забиваются в пользовательский словарь, что со временем снижает точность проверки.
Правила и шаблоны: грамматика в виде кода
Второй подход основан на наборе формализованных грамматических и пунктуационных правил. Разработчики описывают типичные ошибки как шаблоны: «если после числительного в таком-то падеже стоит существительное с такой-то формой, сигнализировать проблему». Система находит в разметке текста эти паттерны и поднимает флаг, предлагая конкретную замену. Преимущество подхода в прозрачности: каждое срабатывание можно объяснить человеком-читаемым правилом. Минус — ограниченное покрытие: новые конструкции, разговорные обороты или сложные вложённые предложения легко «пробивают» даже очень плотный набор правил, а обновление базы требует участия лингвистов и программистов.
Машинное обучение и нейросети

Современные утилиты всё чаще применяют статистические модели и нейросетевые архитектуры. В такой схеме система обучается на больших коллекциях размеченных текстов, где для каждой ошибки уже есть правильный вариант. Диаграмма процесса выглядит так: «Корпус → Обучение модели языка → Фаза предсказания: ввод текста → Оценка вероятности последовательности токенов → Выявление аномалий → Предложение исправлений». Модели учитывают дальний контекст и стилистические закономерности, что позволяет ловить сложные грамматические сбои. Однако цена — потребность в вычислительных ресурсах, сложность интерпретации решения и необходимость регулярного дообучения.
Онлайн-сервисы против офлайн-утилит
Онлайн проверка орфографии и грамматики текстов удобна тем, что пользователь получает доступ к свежим словарям, обновлённым моделям и общему языковому корпусу без ручной установки. Такие решения легко интегрировать в браузер или корпоративный портал, а ресурсоёмкие части переносятся на сервер. С другой стороны, офлайн-утилиты выигрывают в автономности и предсказуемости времени отклика, что особенно важно для защищённых сред и встроенных систем. Выбор между ними — всегда компромисс между приватностью, качеством проверки и требованиями к инфраструктуре.
Интегрированные редакторы и плагины
Отдельная категория — онлайн редактор текста с проверкой орфографии и стиля, который совмещает ввод, анализ и рекомендации в одном интерфейсе. Пользователь сразу видит подсветку, пояснения и варианты переписывания фразы, не переключаясь на внешние приложения. Плагины к IDE или офисным пакетам идут дальше и учитывают специфические словари проекта, терминологию доменной области, шаблоны имён переменных. Внутренняя диаграмма таких решений обычно добавляет шаг «Адаптация к контексту проекта → Кэширование пользовательских решений», благодаря чему система меньше навязывает правки там, где автор уже явно указал предпочтительный вариант.
Сравнение подходов: словари, правила, модели
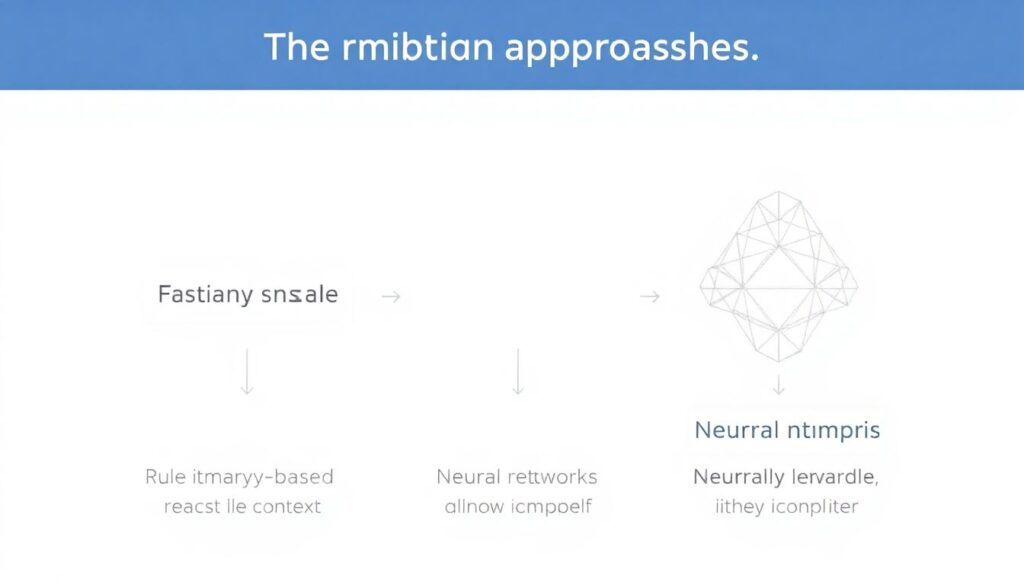
Если сравнивать трём основным подходам — словарному, правил-ориентированному и нейросетевому, — то получается довольно наглядный баланс. Словари обеспечивают скорость и стабильность, но практически не реагируют на контекст. Правила повышают способность ловить грамматику, однако неизбежно остаются неполными и требуют ручного сопровождения. Нейросети, напротив, способны подстраиваться под реальное употребление языка и даже под стилистический профиль, зато вводят элемент вероятностной неопределённости: иногда исправление выглядит грамотно, но плохо ложится на авторский замысел, и это приходится дополнительно контролировать.
Пошаговый сценарий работы утилиты
Рассмотрим, как типичный пользователь взаимодействует с системой в реальном сценарии. Допустим, журналист вставляет черновик статьи в веб-интерфейс. Внутренне это превращается в цепочку: «1) Разбор структуры документа; 2) Выделение цитат и кода; 3) Прогон орфографии по словарю; 4) Запуск грамматических правил; 5) Нейросетевая проверка стилистики; 6) Агрегация подсказок и ранжирование; 7) Показ правок в интерфейсе с возможностью принять или отклонить». Технически каждый шаг может быть реализован отдельным микросервисом, а клиент видит лишь набор подчёркиваний и компактное окно с рекомендациями.
Онлайн-сервисы против локальных утилит: практическое сравнение
Если говорить о пользовательском опыте, онлайн-платформы выигрывают за счёт простоты доступа и постоянного обновления. Тот же сервис автоматической проверки и исправления орфографических ошибок делегирует всю тяжёлую обработку на сервер, что удобно для мобильных устройств и слабых ноутбуков. Локальные же утилиты лучше предсказуемы по задержкам, могут работать без интернета и проще вписываются в строгие политики безопасности. В корпоративных средах часто комбинируют оба подхода: серверный модуль внутри периметра и лёгкие клиенты на рабочих станциях, синхронизирующие словари и пользовательские настройки.
Грань между орфографией и редактированием
Современные решения редко ограничиваются простым поиском неправильных букв. Системы начали предлагать переформулировки, упрощать сложные предложения, подсказывать более точные термины. С технической точки зрения это уже отдельный слой — модуль редакторских рекомендаций, использующий модели перефразирования и эвристики читабельности. Таким образом, утилита из инструмента контроля превращается в ассистента по редактированию. Здесь особенно важна деликатность алгоритма: он должен уметь отступить, когда встречает художественный текст, диалоги или сознательно нарушенную норму ради выразительности.
Коммерческие решения и выбор софта
На рынке присутствуют и бесплатные утилиты, и платные корпоративные системы, и облачные подписки с расширенными функциями. Решая, стоит ли купить софт для проверки орфографии и редактирования текста, компании обычно оценивают несколько параметров: качество языковой поддержки для конкретной отрасли, возможности интеграции по API, управление словарями, отчётность и аудит изменений. Технически продвинутые решения внедряются как часть CI/CD-пайплайна документации или как шлюз для электронной переписки, автоматически контролирующий формальные письма на наличие грубых грамматических ошибок.
Онлайн и офлайн: гибридный путь
Многие современные платформы идут по пути гибридной архитектуры. Базовая проверка орфографии и простая грамматика выполняются локально, быстро и без зависимости от сети, а более сложный стилистический анализ передаётся в облако. Текстовая диаграмма здесь выглядит как «Локальный модуль → Предварительный анализ → Отбор сложных фрагментов → Шифрование → Облачный сервис → Расшифровка результатов и слияние правок». Такой подход снижает нагрузку на сервер, уменьшает объём передаваемых данных и даёт пользователю контроль над приватностью, при этом сохраняя преимущества актуальных языковых моделей.
Выводы: как подбирать утилиту под свои задачи
Выбор инструмента сильно зависит от сценария использования. Для редких проверок достаточно простого плагина в браузер, выполняющего базовую орфографию. При регулярной работе с контентом критичны устойчивые грамматические и стилистические подсказки, удобный интерфейс отклонения правок и поддержка командной работы. Разработчикам и техническим писателям полезнее решения с API и возможностью тонкой настройки словарей проекта. В любом случае полезно помнить, что даже самая продвинутая утилита остаётся помощником, а не окончательным арбитром, и требует осознанного отношения к предлагаемым изменениям.
Комментарии